Published December 21, 2019
by Doug Klugh
Plug-n-Play
Build high quality, loosely coupled architectures by separating high-level policies from low-level details. Encapsulate responsibilities into software modules, while using the Dependency Inversion Principle to create independently deployable plugins. This is achieved by creating boundaries that separate use cases from low-level implementations, then inverting the source code dependencies between them. This will ensure that rate calculations (for example) will not have to be recompiled or redeployed with changes to the database, user interface, or unit tests. These low-level implementations should always be designed as plugins to the use cases. This makes it very easy to swap implementations for data persistence, user interfaces, presentations, or even test doubles.
Figure 1 below illustrates a simple example of the Dependency Inversion Principle. Initially, the switch was directly dependent on the lamp, as if it were hard wired to the lamp. By removing that dependency and inserting an abstract class (the ISwitchClient interface) between the Switch class and the Lamp class, that declares the Toggle function, we were able to make that function polymorphic and decouple the lamp from the switch. Now the Switch class uses the ISwitchClient interface and the Lamp class implements it.
While the Switch class still has a runtime dependency on the Lamp class, it no longer has a compile time dependency on it. Both the Switch and the Lamp have source code dependencies on the interface. Note that the source code dependency of the Lamp class upon the interface points in the opposite direction of the runtime dependency of the Switch upon the Lamp. Inverting dependencies is how we create boundaries between software modules. And creating boundaries is the method by which we create plugins. We are now able to swap the lamp for any other appliance, allowing the switch to control more than just the lamp.
In this example, a module would be created by bundling the Switch class with the ISwitchClient interface and creating a separate plug-in for the each of the applicances (lamp, fan, etc.).

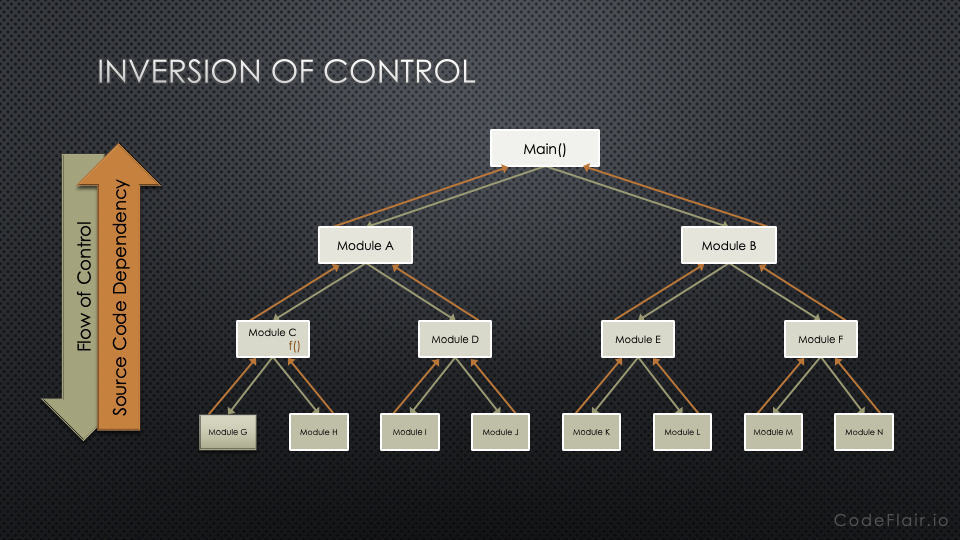
Figure 2 below shows the inversion of source code dependencies so they oppose the flow of control. This inversion creates architectural boundaries (or seams) between software modules, making the call to function f() in module C, polymorphic. While module A still has a runtime dependency on module C, it no longer has a compile time dependency on it.
This is one of the big advantages to using object-oriented languages. Polymorphism gives us the ability to create one module calling another yet having the source code dependency point against the flow of control. This is significant because it give us control over our dependency structure. We can now reduce coupling and avoid writing Fragile, Rigid, and Immobile software.
The example below illustrates how to improve testability through application of the Dependency Inversion Principle. This is a very effective method of isolating the System Under Test (SUT), enabling the substitution of test doubles in place of dependencies.